뉴런들이 작은 local receptive field를 가진다.
Local의 의미는 보이느 것 중 일부 범위 안에 있는 시각 자극에만 반응하다는 의미이다.
여러 local receptive field의 영역은 서로 겹칠 수 있고, 이를 합치면 전체 시야를 감싼다.
simple cell은 직선에만 반응, complex cell은 더 큰 수용소를 가지고 있으며 더 복잡한 패턴에 반응한다.

Yan LeCun, Leon Bottu, Yoshua Bengio, Patrick Haffner가 발표한 수표 손 글씨 숫자를 인식하는 딥러닝 구조
LeNet-5, CNN의 초석이 되었다.
CNN Progress(General)
input->padding->convolutional layer->pooling->convolutional layer->pooling->…->flattering->output
Image Data
이미지를 정형 데이터화 한다.(컴퓨터로 식별 가능한 형태로 데이터를 변환)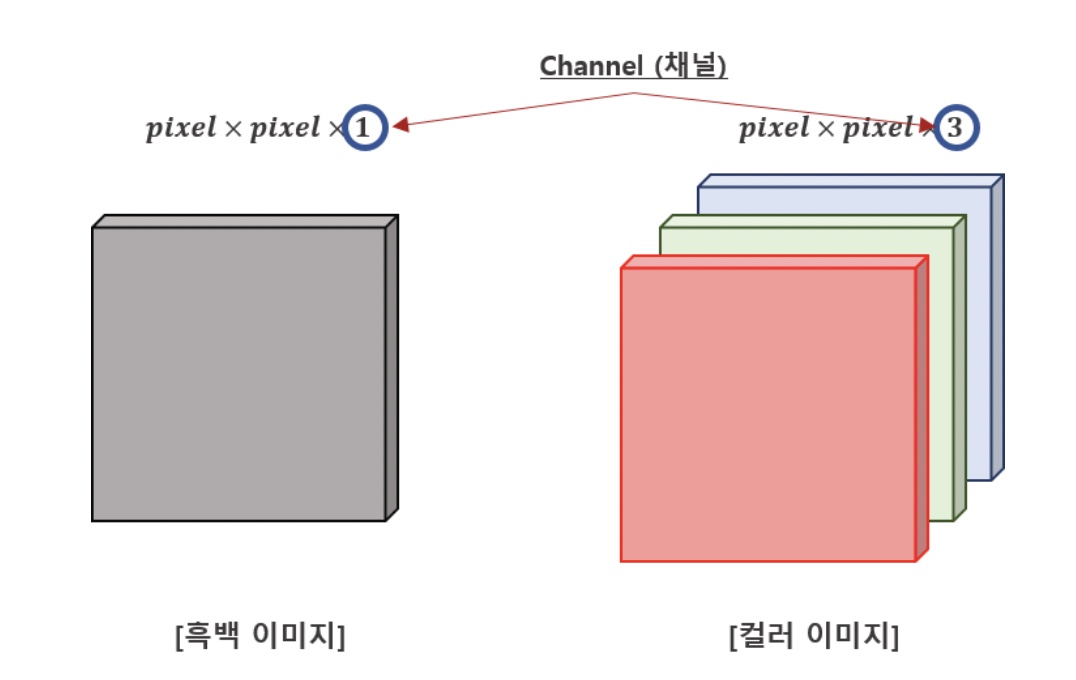
이미지 해상도(pixel x pixel 외에 겹쳐지는 부분을 Channel(채널)이라고 한다.
흑백의 경우 1, 컬러의 경우 3, RGBA의 경우 4(A은 밝기의 Alpha)
Convolutional Layer(합성곱 층)
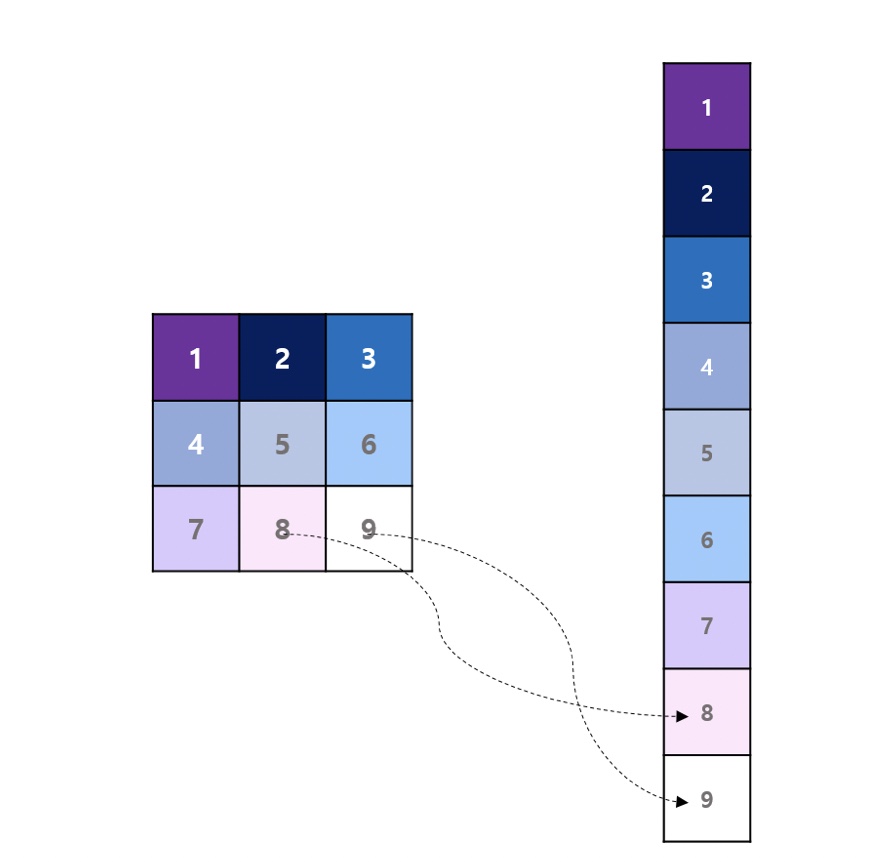
ex) 3x3 픽셀의 흑백이미지
일반 딥러닝 구조로 이미지를 분석할 때, 3x3 배열을 위처럼 펼쳐서(Flattering) 각 픽셀에 가중치를 곱하여 은닉층으로 연산 결과를 전달했다.
이미지는 특성상 각 픽셀간에 밀접한 상관 관계를 가지고 있다. Flattering 해서 분석하면 데이터의 공간적구조를 무시하는 계산이다.
이미지 데이터의 공간적인 특성을 유지하는 것이 convolutional layer의 등장에 큰 동기가 되었다.
Convolution(합성곱)
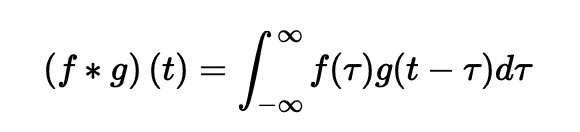
합성곱의 정의를 그대로 이해하면, y축 기준 좌우가 반전이 된 함수 g를 우측으로 t 만큼 이동한 함수 g(t-T)와 f(T)를 곱해진 함수의 적분이다.
예시)
 f와 g의 Convolution
f와 g의 Convolution
f와 g의 Convolution Cross-correlation

합성곱에서 g를 y축 반전시키지 않으면, Cross-correlation이다.
Convolutional Layer의 연산법은 정확하게는 cross-correlation이다.
CNN에서는 가중치를 학습하기 때문에 정확히 구분할 필요는 없음
Convolutional Layer(합성곱 층)

Convolutional Layer는 사람이 실제로 보는 것을 3x3 픽셀을 전체를 인식하는 것이 아닌,
일부분(위에서 빨간상자(5, 6, 8, 9))을 수용역역(receptive field)에 연결되어 복합적으로 해석하는 것이다.

좌측은 4x4 흑백 픽셀 값이고,
우측을 좌측의 이미지를 투영하여 convolution(합성곱연산)을 하는 필터(filter)로 커널(kernel), 윈도우(window)라고 부른다.
픽셀 값은 입력값(input)이 되고, 필터 값은 가중치(weight)가 된다.
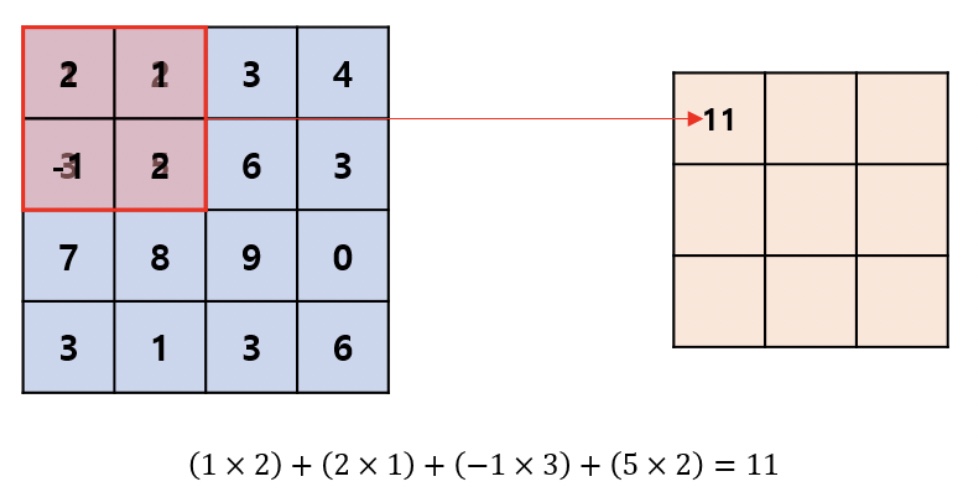
위와 같이 픽셀에 필터를 씌우듯 계산을 수행
(대응되는 숫자끼리 곱한 뒤, 모든 숫자를 더해줌)
합성곱 연산의 결과를 특성(feature)라고 한다.
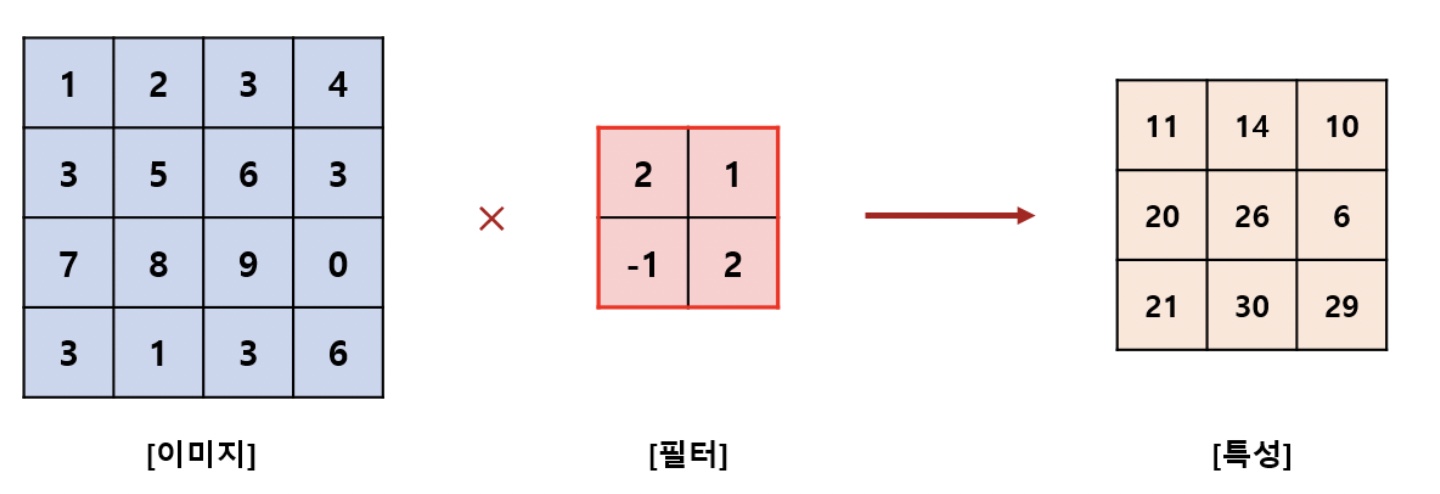
만약 이미지를 Flattering했다면, 16개의 가중치를 학습해야 된다.
convolutional layer을 도입하면, 학습할 가중치가 4개로 줄었고, 연산의 수도 획기적으로 감소한다.

위와 같이 편향(bias)를 더해주기도 한다.
Local Connectivity

Convolutional Layer의 convolution 과정은 입력데이터의 일부만 은닉층과 연결된다.
이를 Local connectivity라고 한다.
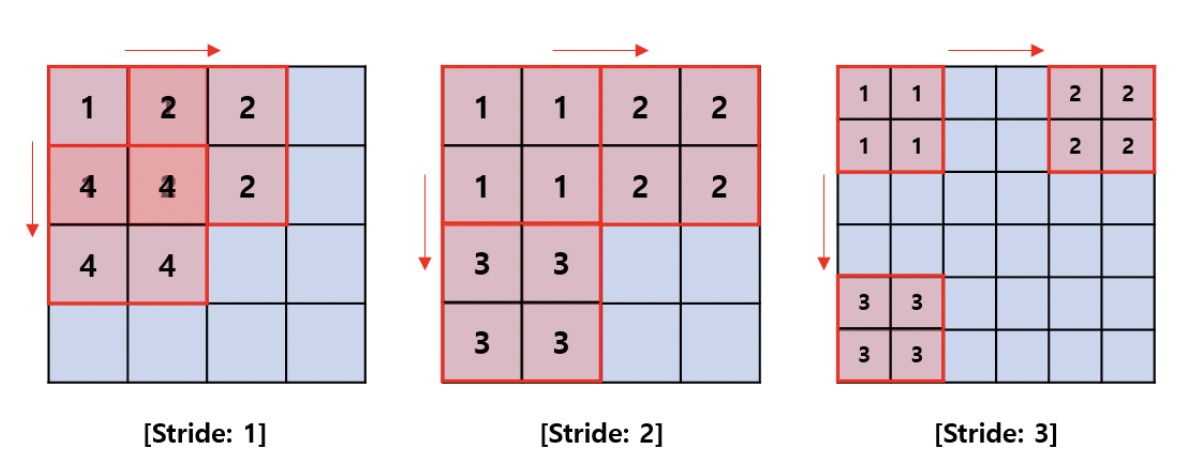
Stride(스트라이드)
필터를 입력 데이터나 특성에 적용할 때 움직이는 간격을 스트라이드(stride)라고 한다.
Padding(패딩)
반복적으로 합성곱 연산을 적용했을 때, 특성의 행렬의 크기가 작아짐을 방지하는 것과 이미지의 모서리 부분의 정보 손실을 줄이고자
이미지 주변에 0으로 채워넣는 방법
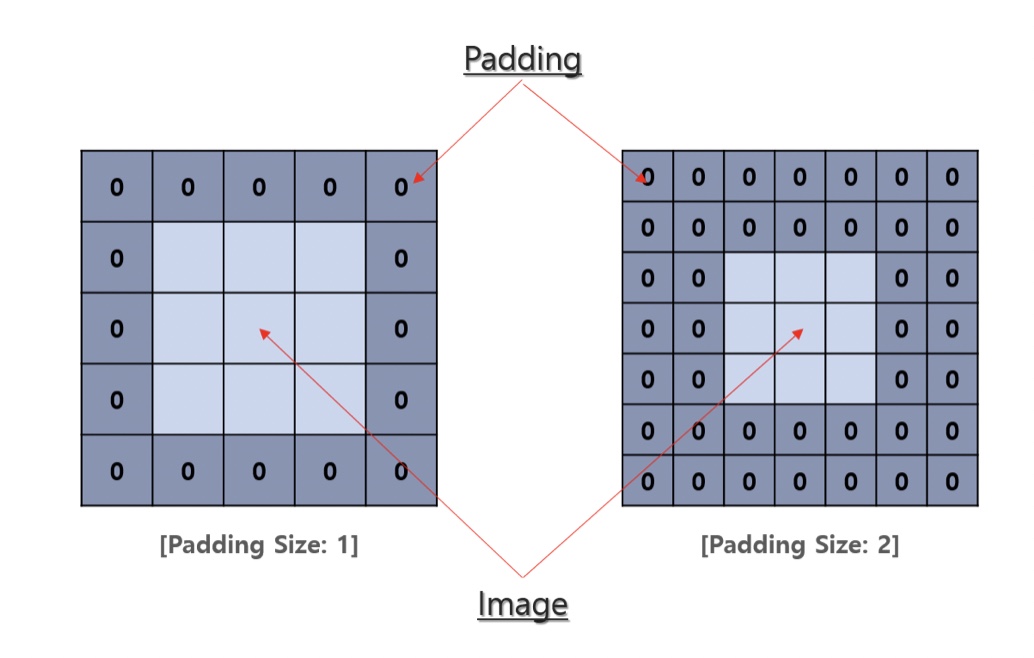
이미지의 중심부가 상대적으로 많이(충분히) 이용되었지만, 모서리 부분의 픽셀은 상대적으로 이용횟수가 적다.
패딩 처리를 하고 나면 이미지의 모든 부분이 중심부처럼 합성곱 연산에 반영되어 정보 손실을 줄일 수 있다.
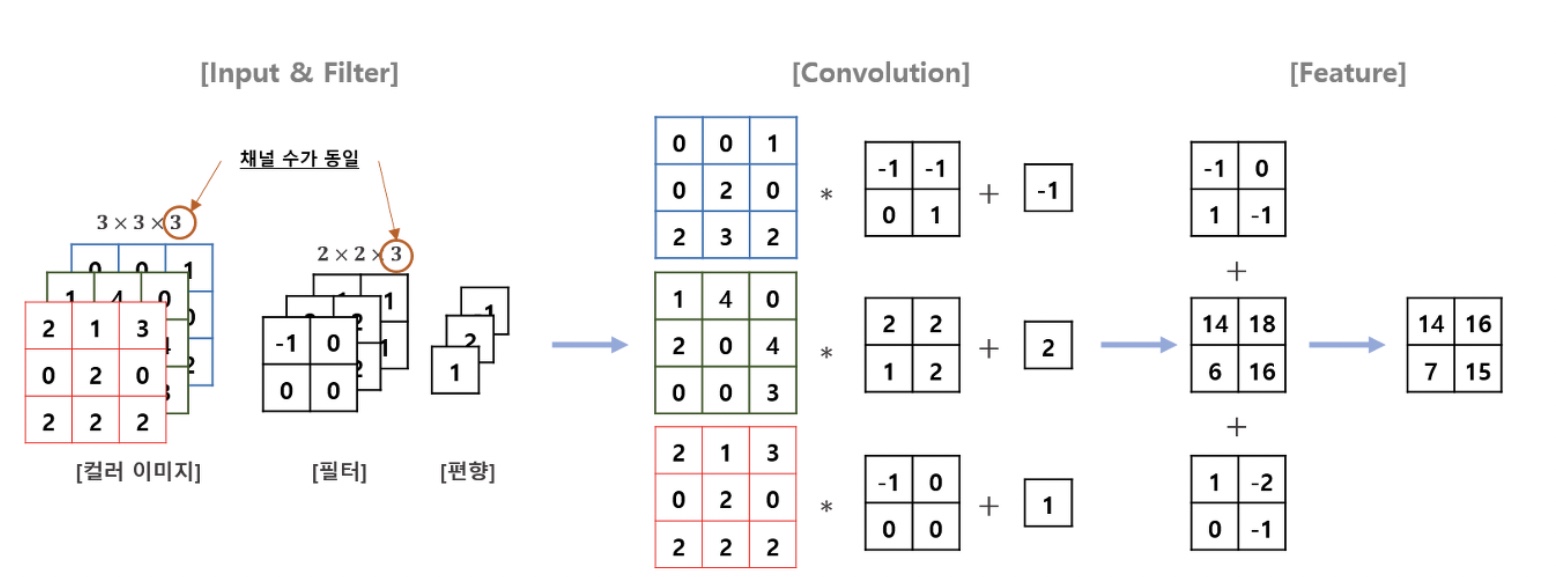
컬러 이미지 합성곱
흑백 이미지와 동일하게 동작하지만, 구분되는 특징이 있다.
필터의 채널이 3이다.(채널이 3이지 개수는 1개임)
RGB 각각 다른 가중치로 Convolution을 하고 결과를 최종적으로 더해준다.
필터가 2개 이상인 합성곱
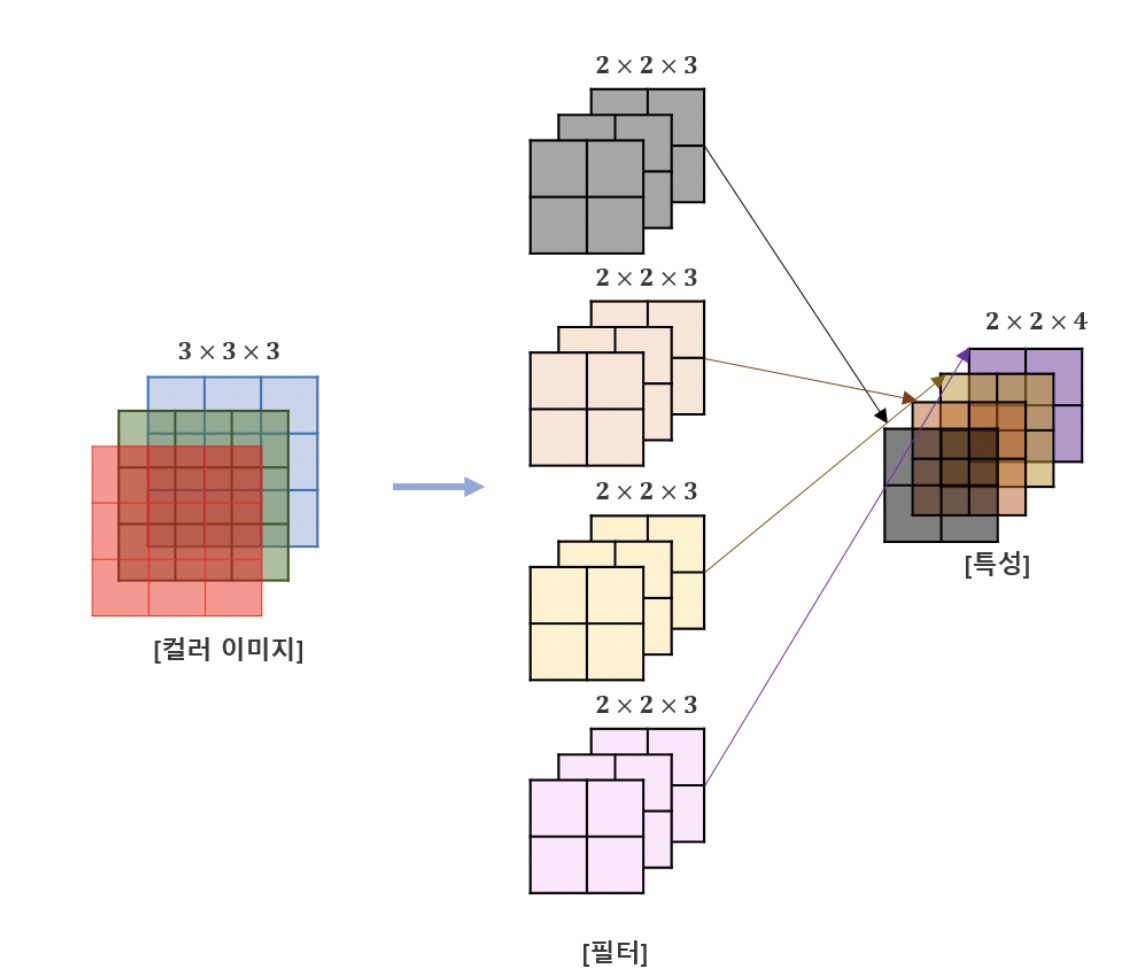
필터에 대해 각각은 특성 추출결과의 채널이 된다.
합성곱 일반화

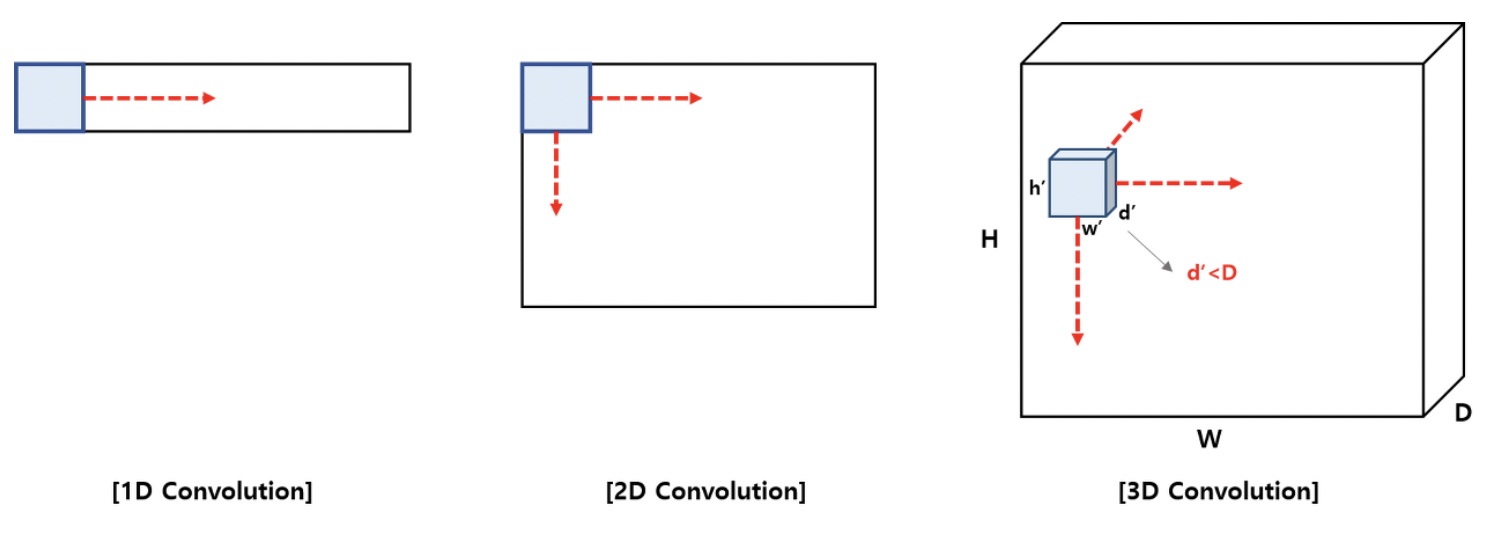
1D Convolution & 2D Convolution & 3D Convolution
합성곱은 이동하는 방향의 수에 따라서 1D, 2D, 3D로 분류된다.
Pooling Layer(풀링층)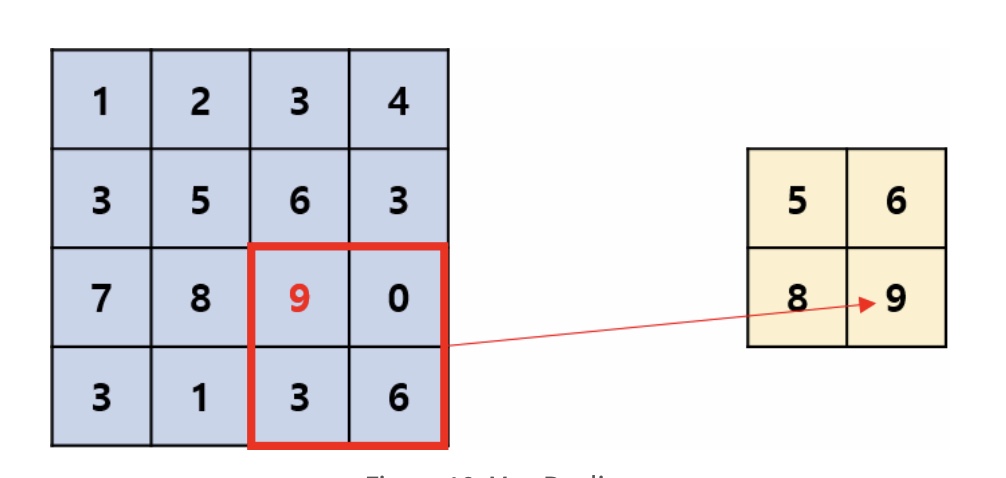 Max Pooling
Max Pooling
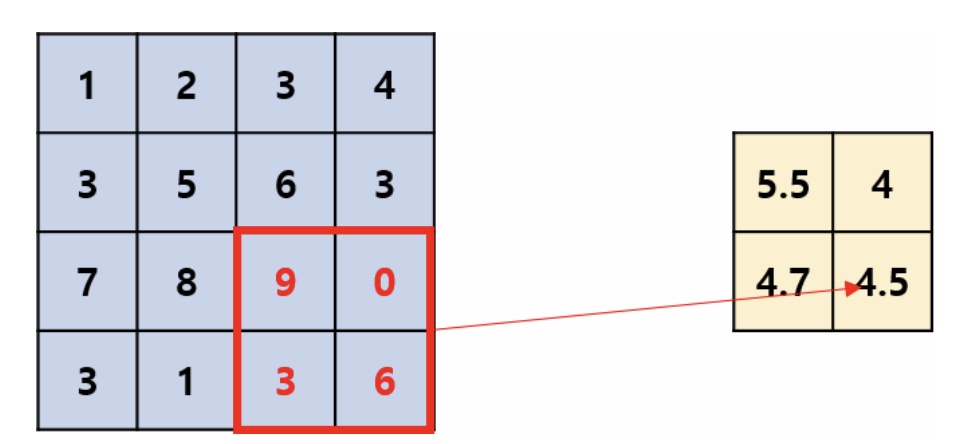 Average Pooling
Average Pooling
풀링층은 데이터의 공간적인 특성을 유지하면서 크기를 줄여주는 층으로 연속적인 합성곱층사이에 주기적으로 넣어준다.
특정위치에서 큰 역할을 하는 특징을 추출하거나 전체를 대변하는 특징을 추출할 수 있다.
크기가 줄어들어 학습할 가중치를 크게 줄일 수 있어 과적합 문제(overfitting problem) 해결에 도움이 된다.
Pooling에는 Max Pooling과 Average Pooling이 있다.
Max PoolingAverage PoolingPooling layer 일반화
